
首先下载ollama:
前往:https://ollama.com/download/windows 下载对应的OS版本*(建议使用命令行,方便调试)
选择本地的文件夹,比如D:\LLM\Models 创建好文件夹后windows使用cd D:\LLM\Models进入目录,或mac/linux使用cd /Users/wangzhiyuan/Documents/llm 都是遵循cd [空格] [路径];Windows右键菜单选择“复制文件地址”;macOS右键然后按住Option选择”Copy “…” as Pathname” 即可获取[路径]信息。这个路径将是我们的工作路径。
如果你图省事,只是想要开箱即用,可以使用 ollama pull [模型名称] 直接下载官方版本使用。
下面这一段in short就是去huggingface.co寻找合适的模型,建议小白选带-it的,登录后输入自己的电脑配置信息进入各个模型后右侧可以查看推荐配置,对话模型无脑IQ4_XS>i1_Q4_K_M>Q4_K_M 不要顶着内存上限选模型。具体可以上网搜视频推荐
如果你想要特质化的模型,想要更针对化的优化后的模型:
前往https://huggingface.co/models 寻找并下载需求模型。对于纯小白可以注册登录后在右侧查看预计显存/内存占用和自己电脑配置的匹配关系。注意不要顶着自己的内存上限选模型,因为要预留KV Cache(上下文缓存)以及系统其他进程包括后期前端应用的内存占用。Windows有独显的一般情况下不建议吃满独显,因为如果KV Cache溢出显存会导致模型速度下降很多,仅略微高于纯CPU(木桶原理,DDR5的带宽显著低于显存,E4B会稍微好一些,但需要特殊配置让模型的部分layers让CPU算或者降低num_gpu参数,KV Cache保留在显存中,可以显著提速。详见koboldcpp的教程)
模型名称一般是”作者/基座-特调方向/特性-量化方式-格式。比如图中的Gemma-4-E4B是基座,-it是Instruction Tuned(指令微调)的缩写。建议小白选择带-it的,因为不需要复杂的调参和配置system prompt就可以开箱即用。后面的-coder是编程优化,这个不明白的可以询问AI(题外话,不用太过于专注于这里的标签描述,除非是-thinking带额外思考,Auro-4o是模拟GPT4o的回答方式或者其他特化的很明显的参数,否则几乎无异。还有混合模型,比如-vl-deepseek或者-vl-GLM-Polaris等,这种智力水平完全看作者水平,调的好是兼顾两者的优点,调的不好就是智力缺陷)大部分情况下首推IQ4,虽然速度稍慢,但是量化后内存占用最小,智力损失较低,性价比一般最高。如果有-i1的后缀说明采用了用算力换内存的算法,赋予常用神经元更高的权重,理论上同等量化下更聪明,一般来说IQ4和Q5差不多聪明,但是内存占用明显小一节,所以性价比更高。一般来说对话模型无脑选IQ4就行了(embedding一般无脑Q8_0, 因为要极致的精度)。但极端情况下苹果的M系列/ARM有一个特殊情况,如果你的内存充足,想要提速,可以使用Q8_0,最小化压缩,性能损失小,速度最快。原理是IQ4和Q4_KM这些压缩后的权重需要现场解压成浮点,这个过程中有性能(算力)损失,而_0意味着无压缩,理论性能损失更低。一般来说只有用ARM的设备,比如苹果/安卓手机等才可能选择这个方式,因为专业显卡NV的算力远超带宽,对于Intel/AMD来说瓶颈在于DDR5的窄带宽,所以都不适用于这个情况。有一个测试方法,使用ollama run [模型] –verbose查看eval rate,计算方式是 如果显著低于带宽,那就说明你可以通过换成_0结尾的提高速度(极其罕见,大部分机器都是算力>带宽)
下载好模型后,这里出现分支(因为Windows和macOS/Linux指令集不一样)
Windows:
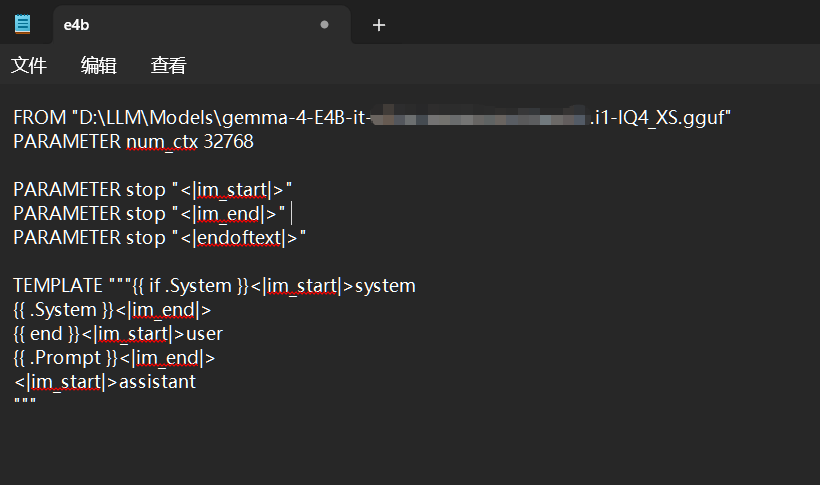
使用资源管理器进入你刚才创建的工作路径,新建一个文件(没有任何后缀)命名随意,建议使用模型名称这样方便自己辨认,编码模式选择UTF-8, 这里的第一行的FROM是你下载的.gguf的模型位置。num_ctx是上下文长度。PARAMETER一般留给前端设置,但对于对话模型一般建议按照下面的template设置。一定记得保存
FROM [Path to your .gguf]
PARAMETER num_ctx 32768
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|endoftext|>"
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
随后在资源管理器的工作路径位置,右键菜单选择“在终端中打开” 输入指令
ollama create [your model name] -f [your file name]
e.g.
ollama create e4b -f e4byour model name是你之后运行的时候使用的,为了方便,建议设置成比较简洁的名字,your file name是你刚才创建的那个文件的名称。如果这一步提示file not found, 请注意查看你刚才保存的那个文件是不是默认保存成了.txt, 改为无后缀。详细操作上网搜。随后我们可以运行模型进行测试:
ollama run [your model name] --verbose
e.g.
ollama run e4b --verbose这里的–verbose是调试参数,可以让我们更详细的看到模型状态和运行瓶颈
macOS/Linux:
Coming Soon
No responses yet